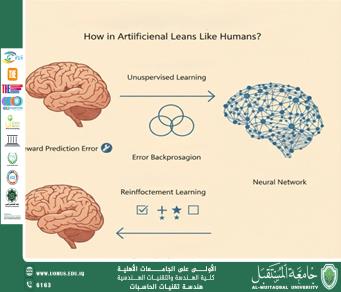
كيف يتعلّم الذكاء الاصطناعي مثل الإنسان؟
المهندس علي عدنان عبد الكاظم<br />يتعلّم الإنسان عبر ثلاث آليات رئيسية: الاقتران / الترابط ( نربط حدثًا بآخر)، التغذية الراجعة المُعلّمة (نعرف الجواب الصحيح فنتعلّم من الخطأ)، والتجربة والخطأ مع المكافأة (نكرّر الأفعال التي تجلب منفعة). تقابل هذه الآليات في الذكاء الاصطناعي: التعلّم غير المُشرف (اكتشاف البِنى/الأنماط)، التعلّم المُشرف (التعلّم من أمثلة معنونة)، والتعلّم بالتعزيز (تعظيم المكافأة بمرور الزمن). هذا التشبيه ليس مجازيًا فقط؛ بل مدعوم بأُطر علمية راسخة في الشبكات العصبية والتعلّم بالتعزيز وعلم الأعصاب الحاسوبي.<br />1.كيف يتعلّم الدماغ؟ ثلاث صور مختصرة<br />1.1.الترابط (Association): إذا تنشطت خليتان عصبيتان سويًا مرارًا، تقوى الوصلة بينهما—“العصبونات التي تنشط معًا تقوى وصلاتها” (Hebbian learning). هذا يفسّر تكوّن الذاكرة الترابطية واكتشاف الأنماط بلا مُعلِّم مباشر. <br />1.2.التعلّم بالتغذية الراجعة المُعلّمة: نرى الإجابة الصحيحة فنصحّح مساراتنا الذهنية تدريجيًا—يقابله خفض “خطأ التنبؤ”.<br />1.3.التجربة-والخطأ والمكافأة: الخلايا الدوبامينية في الدماغ تُشفِّر خطأ توقّع المكافأة؛ إذا كانت النتيجة أفضل/أسوأ من المتوقّع، نعدّل سلوكنا. هذا مطابق رياضيًا لفكرة خطأ التنبؤ بالمكافأة في التعلّم بالتعزيز.<br />2.النظير الاصطناعي: كيف تتصرّف خوارزميات التعلّم؟<br />(أ) التعلّم غير المُشرف (Unsupervised)<br /> *الفكرة: إيجاد بنية خفية في البيانات من دون تسميات (مثل التجميع Clustering أو التمثيلات Representation Learning).<br /> *التشابه البشري: أشبه بتكوّن الروابط الترابطية في الدماغ (Hebbian).<br />(ب) التعلّم المُشرف (Supervised)<br />(ج) التعلّم بالتعزيز (Reinforcement Learning)<br />3.مفاهيم أساسية <br /> الشبكة العصبية (Neural Network): دوال مركّبة من طبقات؛ كل طبقة تُجري تحويلًا بسيطًا، وتراكيبها تُنتج سلوكًا معقّدًا. الأوزان هي “ذاكرة” النموذج.<br />التدريب (Training): تكرار حساب الخسارة ثم تحديث الأوزان بتدرّجها.<br />معدل التعلّم (Learning Rate): حجم خطوة التحديث؛ كبير جدًا ⇒ يتذبذب، صغير جدًا ⇒ يتباطأ—توازُن مهم في جميع النماذج. <br />التعلّم المنهجي/بالمناهج (Curriculum Learning): نبدأ بالمسائل السهلة ثم الأصعب—تمامًا كالتعليم البشري—ما يسرّع التقارب ويحسّن الحلول. <br />4.كيف تعلّم AlphaGo لعب الشطرنج الآسيوي (Go)؟<br />المرحلة 1: تعلّم مُشرف من ملايين النقلات البشرية لتقليد الخبراء (شبكة سياسات Policy).<br />المرحلة 2: تعلّم بالتعزيز عبر اللعب الذاتي لتجاوز مستوى البشر.<br />المرحلة 3: بحث شجري (Monte-Carlo Tree Search) يستعين بالشبكات لتقييم الحركات بسرعة.<br /> *النتيجة: AlphaGo هزم بطل أوروبا 5–0 ثم فاز على لي سي دول (4–1)، مبيّنًا كيف يُمزج التعلّم المُشرف، والتعزيز، والبحث لتحقيق “حدس” يفوق البشر أحيانًا.<br />خاتمة<br />يتقاطع تعلّم الإنسان والآلة في مبادئ: تعزيز الوصلات النافعة ( Hebbian / تمثيلات )، تصحيح الخطأ ( Backprop / خسارة ) ، وتعظيم المكافأة( RL /الدوبامين). هذا التشابه يفسّر لماذا نجحت الشبكات في مهام بدت “بشرية” مثل Go: دمج خبرة بشرية مُشرفة مع لعب ذاتي مُعزَّز وبحثٍ فعّال. لكننا ما زلنا بعيدين عن التعلّم الشامل المرن للبشر—وهنا تكمن البحوث الجارية: المناهج، والتعلّم الذاتي الإشراف، والتعلّم القليل العينات، والتعلّم السببي، وغيرها.<br />جامعة المستقبل الجامعة الاولى