
مقالة علمية بعنوان . مقارنة بين خوارزميات التعلم الخاضع للإشراف وغير الخاضع للإشراف الباحث : بنين ناظم
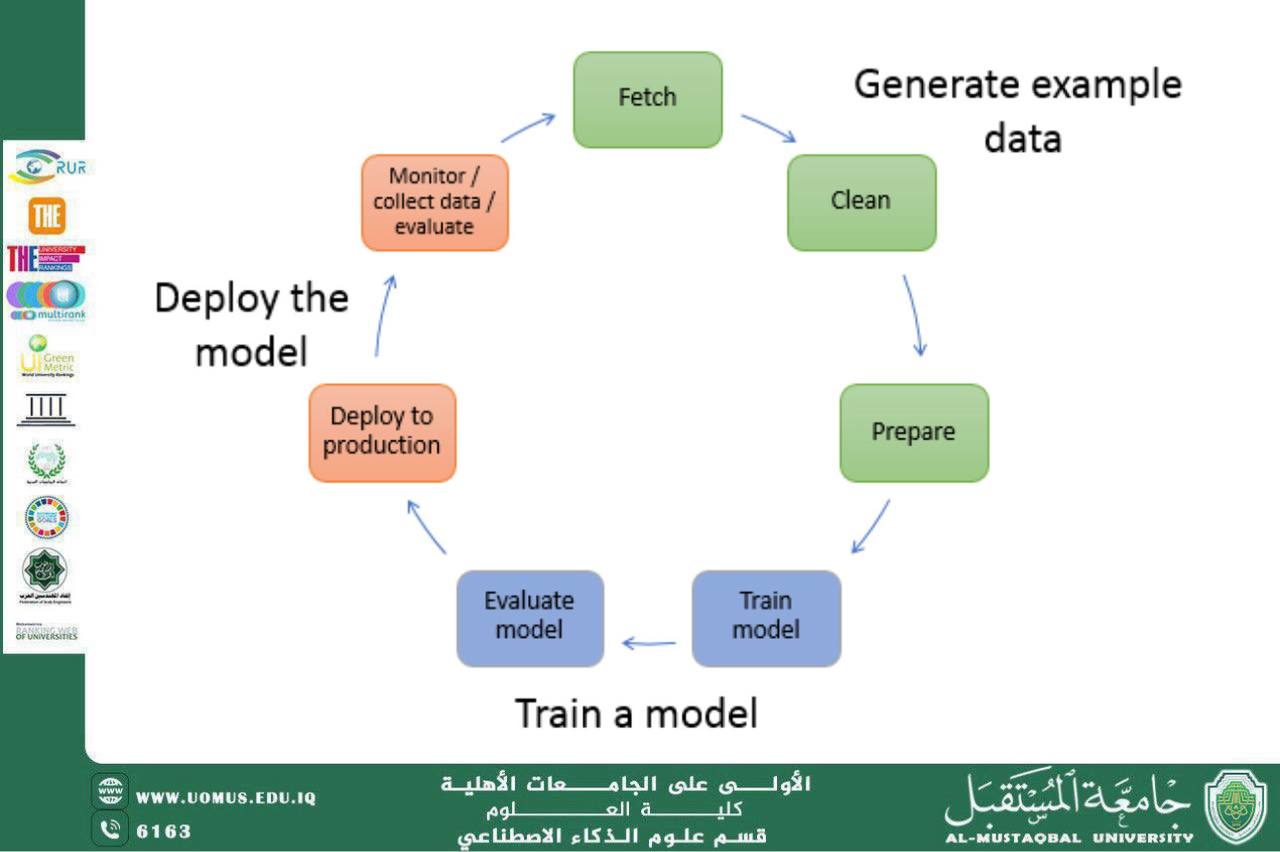
تعتبر خوارزميات التعلم الآلي أحد أهم فروع الذكاء الاصطناعي، وتُقسم عادةً إلى نوعين رئيسيين: التعلم الخاضع للإشراف والتعلم غير الخاضع للإشراف. يعتمد التعلم الخاضع للإشراف على وجود بيانات مدخلة مُعلمة مسبقًا، حيث تتضمن كل عينة من البيانات مخرجات معروفة، ويهدف النموذج إلى تعلم العلاقة بين المدخلات والمخرجات للتنبؤ بنتائج جديدة. ومن أبرز تطبيقاته تصنيف الصور والنصوص، التنبؤ بالقيم الرقمية، وتشخيص الأمراض. تتميز هذه الخوارزميات بالدقة العالية عند توفر كمية كافية من البيانات المصنفة، لكنها تتطلب جهدًا كبيرًا في تجهيز البيانات المعلّمة مسبقًا.
أما التعلم غير الخاضع للإشراف، فيعتمد على بيانات غير مُعلمة، ويهدف إلى اكتشاف الأنماط أو التجمعات المخفية داخل البيانات دون معرفة مسبقة بالمخرجات. من أبرز تطبيقاته تحليل البيانات، تجميع العملاء وفقًا لسلوكهم، وتقليل الأبعاد للبيانات الكبيرة. يتميز هذا النوع من التعلم بالقدرة على التعامل مع كميات ضخمة من البيانات غير المنظمة، ولكنه قد يواجه صعوبة في تفسير النتائج وربطها بتطبيقات عملية محددة.
يمكن القول إن كل نوع من خوارزميات التعلم له مزاياه وتحدياته. التعلم الخاضع للإشراف يعطي دقة عالية واستجابة متوقعة عند توفر بيانات مصنفة جيدًا، بينما يوفر التعلم غير الخاضع للإشراف مرونة أكبر في استكشاف الأنماط الخفية في البيانات الكبيرة والمعقدة. ومن هنا، فإن اختيار الخوارزمية المناسبة يعتمد على طبيعة البيانات المتاحة، الهدف من التحليل، والموارد المتوفرة لتدريب النماذج