
A scientific article titled: A Comparison Between Supervised and Unsupervised Learning Algorithms. Researcher: Banin Nazim
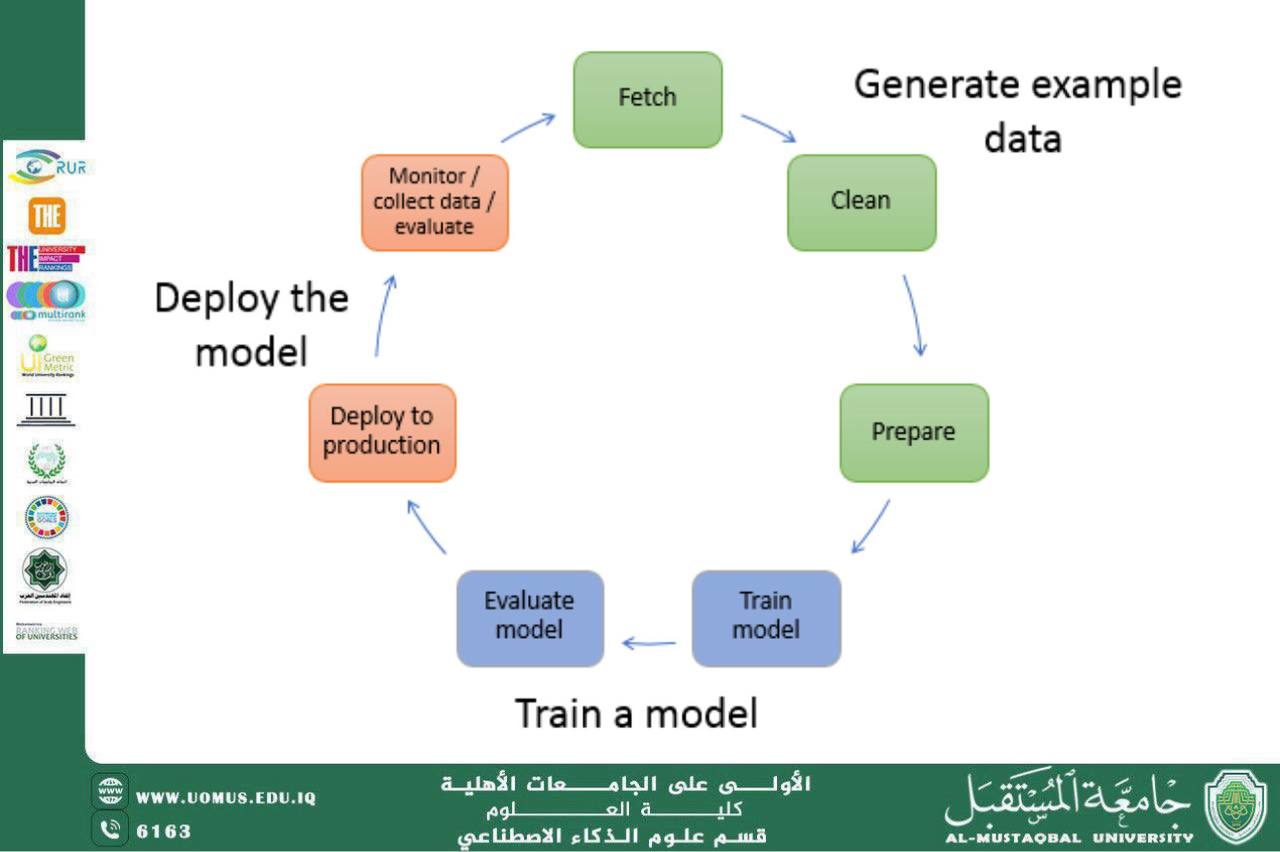
Machine learning algorithms are one of the most important branches of artificial intelligence and are generally divided into two main types: supervised learning and unsupervised learning. Supervised learning relies on pre-labeled input data, where each data sample has a known output. The model aims to learn the relationship between inputs and outputs to predict new results. Its most common applications include image and text classification, numerical prediction, and disease diagnosis. These algorithms are highly accurate when a sufficient amount of labeled data is available, but they require significant effort in preparing and labeling the data in advance.
Unsupervised learning, on the other hand, relies on unlabeled data and aims to discover hidden patterns or clusters within the data without prior knowledge of the outputs. Its main applications include data analysis, customer segmentation based on behavior, and dimensionality reduction for large datasets. This type of learning is highly capable of handling large amounts of unstructured data, but it may face difficulties in interpreting the results and linking them to practical applications.
It can be concluded that each type of learning algorithm has its advantages and challenges. Supervised learning provides high accuracy and predictable results when well-labeled data is available, whereas unsupervised learning offers greater flexibility in exploring hidden patterns within large and complex datasets. Therefore, choosing the appropriate algorithm depends on the nature of the available data, the objective of the analysis, and the resources available for training the models.