مقالة علمية بعنوان بناء نموذج لغوي لمعالجة اللهجة العراقية باستخدام تقنيات التعلم العميق الباحث : بنين ناظم
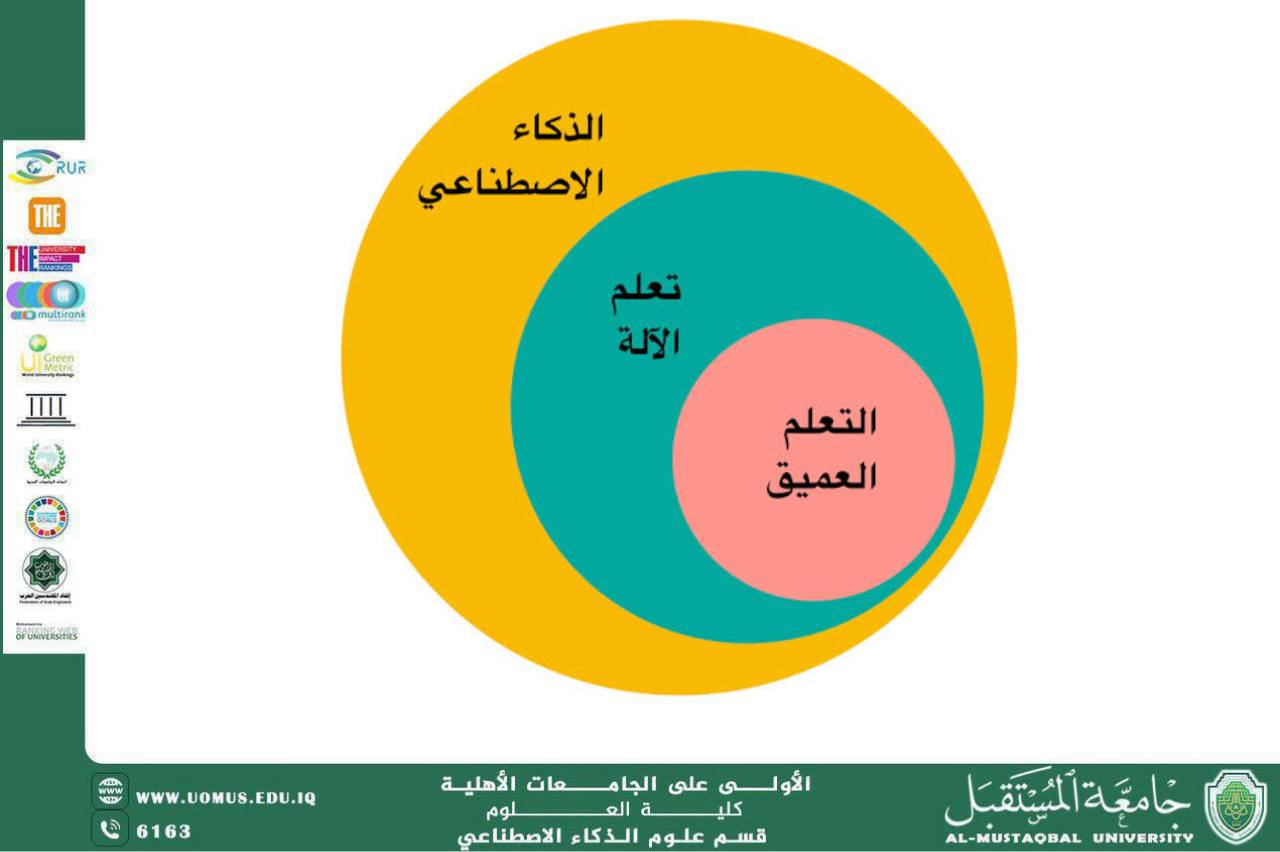
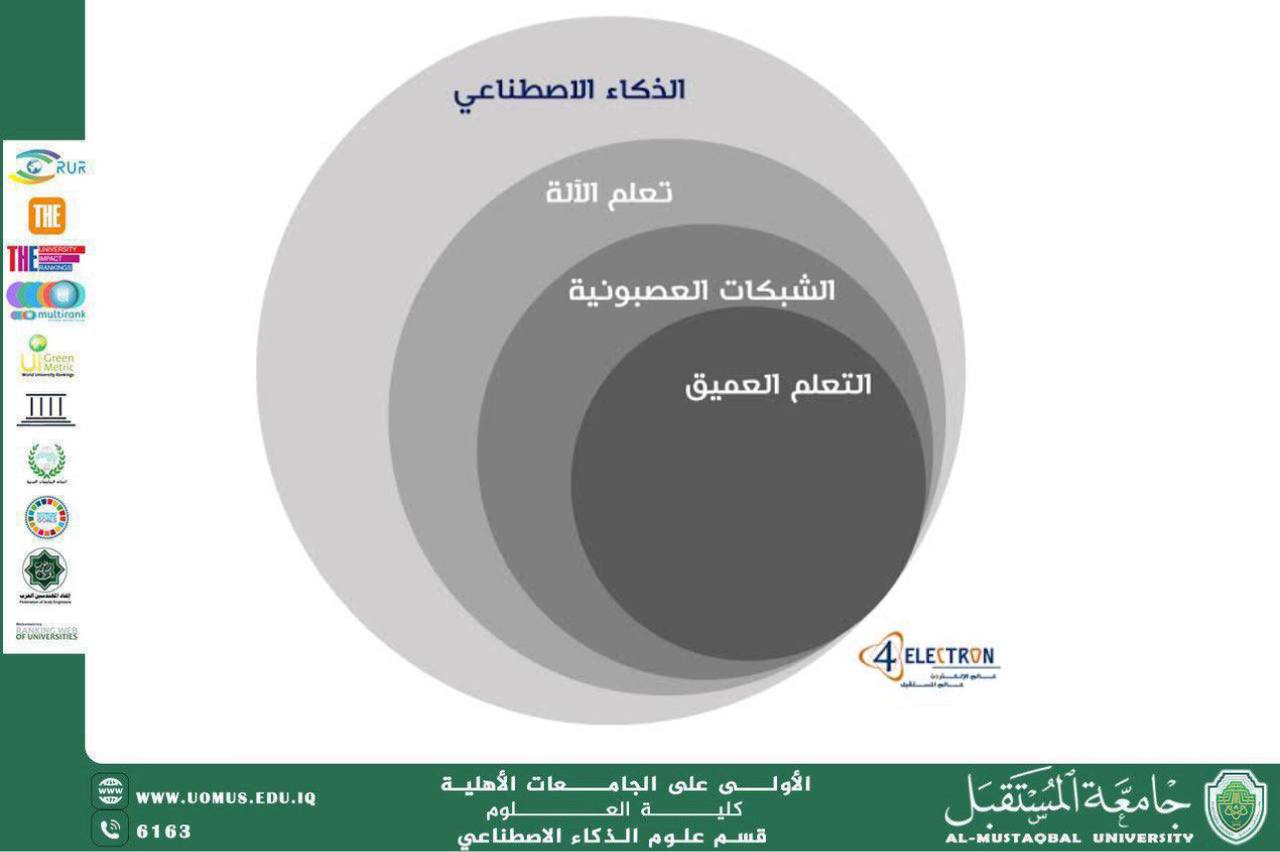
تُعد معالجة اللغة الطبيعية من أكثر المجالات الحيوية في الذكاء الاصطناعي، حيث تهدف إلى تمكين الحواسيب من فهم النصوص والكلام البشري بطريقة قريبة من الفهم البشري. ومن بين التحديات الكبيرة في هذا المجال معالجة اللهجات المحلية، وفي مقدمتها اللهجة العراقية التي تتميز بتنوعها واختلافاتها بين المحافظات والمناطق، فضلاً عن احتوائها على مصطلحات غير موجودة في اللغة العربية الفصحى. يهدف بناء نموذج لغوي لمعالجة اللهجة العراقية إلى تطوير نظام قادر على فهم وتحليل النصوص والكلام باللهجة المحلية، وتمييز الكلمات والعبارات المستخدمة في سياقات مختلفة. يعتمد هذا النموذج على تقنيات التعلم العميق، مثل الشبكات العصبية العميقة ونماذج التحويل (Transformers)، والتي أثبتت قدرتها الكبيرة على التعامل مع اللغة الطبيعية والتعرف على الأنماط المعقدة. يتم تدريب النموذج على مجموعات بيانات ضخمة تحتوي على نصوص باللهجة العراقية من مصادر متعددة تشمل وسائل التواصل الاجتماعي، المحادثات الصوتية، والمنتديات الإلكترونية، وذلك لضمان تغطية أكبر تنوع لغوي ممكن. كما يتيح هذا النظام إمكانية تطبيق تقنيات التعرف على الكلام، بحيث يمكن تحويل الكلام العراقي إلى نصوص مكتوبة، ما يفتح المجال لتطوير تطبيقات متعددة مثل الترجمة الفورية، أنظمة المساعد الذكي، وتحليل المشاعر. من خلال هذا النموذج، يمكن أيضًا دراسة التغيرات اللغوية ومتابعة تأثير التطورات الاجتماعية والثقافية على اللهجة العراقية، وهو ما يضيف بعدًا بحثيًا هامًا. كما يسهم النموذج في دعم المحتوى الرقمي المحلي وتمكين المطورين والباحثين من إنشاء تطبيقات ذكية تتفاعل مع المستخدمين باللغة المحلية، ما يعزز من انتشار التكنولوجيا بشكل فعّال وميسر. وتواجه عملية بناء النموذج تحديات متعددة، أبرزها نقص المصادر الموثوقة، التباين الكبير بين الكلمات واللهجات، إضافة إلى وجود تأثير اللغة الفصحى على بعض النصوص. ومع ذلك، يوفر استخدام التعلم العميق آليات قوية لاكتشاف الأنماط اللغوية ومعالجتها بطريقة دقيقة، مع إمكانية تحسين النموذج باستمرار من خلال التغذية الراجعة والمراجعة البشرية. ويعكس هذا المشروع أهمية دمج الذكاء الاصطناعي مع البحث اللغوي المحلي، ويشكل خطوة مهمة نحو تطوير أنظمة ذكية قادرة على فهم وتفاعل اللهجات العربية المحلية بشكل فعّال، بما يسهم في تعزيز الاستخدام التقني للغة العربية وتسهيل الوصول إلى الخدمات الرقمية لجميع شرائح المجتمع